
提出需求
不知道什么时候开始喜欢在上下班通勤路上听听播客,大约是日谈公园入的坑,个人比较喜欢的一些播客节目有:
- 淼叔的犯罪探案故事;
- 奶杨杨原博士聊各种故宫里的八卦;
- 柯紫小姐姐各种科普的日知录;
- 啤酒事务局入坑了精酿;
- TSP怪奇档案听听ghs的聊斋故事……
但是iOS14开始,苹果自带的播客在CarPlay中经常会遇到循环播放的bug:播放没几分钟,就会跳回开始,然后无限重复。因此不得不寻求播客App的替代品。
而且也因工作需要,想在通勤时听一些《民法典》法条解读,虽然存在手机里面用播放器也能播放,但是nPlayer并不能很好支持CarPlay。
因此,就大致有了如下的需求:
- 支持CarPlay
- 播放流畅(没有恶性bug)
- 支持向前、向后回放15s或30s
- 支持自定义音频导入
各App优缺点(未做深度评测,如果你觉得好用,那就是你对)
| App | 优点 | 缺点 |
|---|---|---|
| 官方播客 | 自带,无需下载App,可自定义RSS订阅 | CarPlay存在致命bug |
| 网易云音乐 | 使用了UnBlockMusic功能听歌,所以对于我来说无需切换App | 不支持自定义音频导入或自定义RSS订阅,CarPlay中无前后15s功能 |
| 小宇宙 | 界面比较漂亮(未测试CarPlay) | 不支持自定义音频导入或自定义RSS订阅,虽然支持OPML导入节目,但是需要从其他App导入 |
| Overcast | 自定义功能比较强 | 本地化不尽人意,UI略丑,播放界面有广告 |
| Moon FM | 界面比较漂亮,CarPlay支持(节目封面加载有一些bug,开发者回应未来版本适配CarPlay api 2.0) | 付费App(不过经常限免);同步需自建数据库; |
Moon FM在少数派也有过多人推荐和介绍,所以这里就不重复造轮子了。
Moon FM官方网站
https://moon.fm/
搭建自定义播客,以《民法典-婚姻家庭编》为例
原理
本来我对于播客这个,也只是听个响,也没有研究过背后运行的逻辑。
经过抓包,发现:
一个播客频道=一个包含每个单集音频地址的XML文件
因此,我们搭建一个播放自己音频的播客,只需要:
- 托管音频
- 生成XML订阅文件
- 托管XML文件
托管音频
云托管&本地转发
一句话原理:利用NAS中Docker挂载阿里云盘,端口转发暴露地址。
- 网页登录阿里云盘后在控制台输入
JSON.parse(window.localStorage.getItem("token"))["refresh_token"];
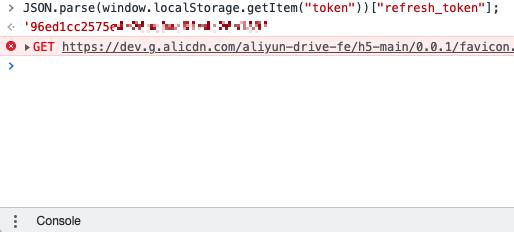
获取token后留着备用;
- 上传文件至阿里云盘;(本地文件先别删,生成XML的时候需要使用)

- 因为我是斐讯N1挂载1T的硬盘作为简易的NAS使用,如使用群晖等类似操作即可。在Docker中挂载阿里云盘,将前面的token填入下面代码,因为要暴露到公网,登录名&密码自行修改;
docker run \
-d --name=webdav-aliyundriver --restart=always -p 8080:8080 \
-v /etc/localtime:/etc/localtime \
-v /etc/aliyun-driver/:/etc/aliyun-driver/ \
-e TZ="Asia/Shanghai" \
-e ALIYUNDRIVE_REFRESH_TOKEN="your_token" \
-e ALIYUNDRIVE_AUTH_PASSWORD="admin" \
-e JAVA_OPTS="-Xmx1g" zx5253/webdav-aliyundriver- 设置端口转发;我的主路由为华硕AC-86u,因此安装了
阿里DDNS和Let's Encrypt插件,只需要设置端口转发即可通过域名+端口的方式访问内网服务,关于如何进行内网穿透或者端口转发在此不赘。
外网访问地址如下:
http://admin:admin@example.com:8080/Podcasts/test/test.mp3本地存放&转发。
一句话原理:存放于NAS并通过FileBrowser分享,最后通过端口转发暴露地址。
- 开启FileBrowser服务(OpenWRT自带,其他系统自行搜索安装)
- 上传文件
- 设置文件分享(整体文件夹分享即可)
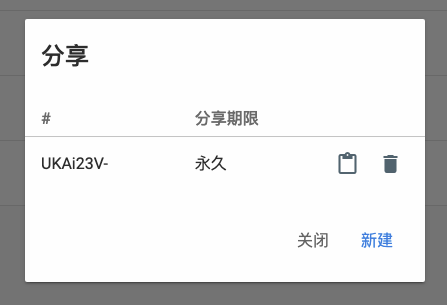
- 分享文件夹后会有随机码,分享链接格式为:
http://example.com:4040/share/yeaQs7rf直接访问链接为:
http://example.com:4040/api/public/dl/yeaQs7rf/test.mp3?inline=true生成XML订阅文件
关于本地文件命名规则:
- 尽可能以下规则命名,这样将会按照顺序生成XML文件,否则以文件名排序,如像法条解读本身文件名中带编号的可不以该规则命名。
- 【00这是一个测试音频.mp3】
- 【01这是另一个测试音频.mp3】
- ……
在对几个热门频道订阅链接抓包分析后发现XML文件结构基本如下(没保留之前的,就把现成的拿出来比划一下):
主要是:
- 频道信息
- 频道名称
- 频道简介
- 频道语言
- 频道Logo及Logo名称
- 单集节目信息
- 单集名称
- 单集简介
- 单集推送日期
- 单集地址、长度、类型(不同后缀音频类型不同,类型参考)
- 单集图片
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom" xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd">
<channel>
<title>民法典之婚姻家庭编</title>
<link></link>
<description>民法典之婚姻家庭编法条解读</description>
<language>zh-cn</language>
<image>
<url>https://android-artworks.25pp.com/fs08/2021/11/23/9/110_0cc601f3d1b5a8de567f2cfd7868ea57_con_130x130.png</url>
<title>民法典之婚姻家庭编</title>
</image>
<item>
<title>婚姻家庭编第1109条</title>
<description>婚姻家庭编第1109条</description>
<pubDate>Thu, Dec 30 2021 13:28:28 +0800</pubDate>
<enclosure length="4141489" type="audio/m4a" url="http://admin:admin@192.168.124.25:8080/Podcasts/%E5%A9%9A%E5%A7%BB%E5%AE%B6%E5%BA%AD%E7%BC%96/%E5%A9%9A%E5%A7%BB%E5%AE%B6%E5%BA%AD%E7%BC%96%E7%AC%AC1109%E6%9D%A1.m4a"/>
<itunes:image href="https://android-artworks.25pp.com/fs08/2021/11/23/9/110_0cc601f3d1b5a8de567f2cfd7868ea57_con.png"/>
</item>
<item>
<title>婚姻家庭编第1100条.</title>
<description>婚姻家庭编第1100条.</description>
<pubDate>Thu, Dec 30 2021 13:28:28 +0800</pubDate>
<enclosure length="3729089" type="audio/m4a" url="http://admin:admin@192.168.124.25:8080/Podcasts/%E5%A9%9A%E5%A7%BB%E5%AE%B6%E5%BA%AD%E7%BC%96/%E5%A9%9A%E5%A7%BB%E5%AE%B6%E5%BA%AD%E7%BC%96%E7%AC%AC1100%E6%9D%A1..m4a"/>
<itunes:image href="https://android-artworks.25pp.com/fs08/2021/11/23/9/110_0cc601f3d1b5a8de567f2cfd7868ea57_con.png"/>
</item>
</channel>
</rss>
知道了文档结构,那么我们就可以利用Python,针对存放音频的文件夹进行遍历并逆序生成XML文件。
#!/usr/bin/python3
# encoding:utf-8
'''
根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML。
'''
from xml.dom.minidom import Document
from urllib import quote
import os
import time
import re
#————————————————自定义区————————————————#
# 频道名称
c_channel_title = "民法典之婚姻家庭编"
# 频道链接
c_channel_link = ""
# 频道简介
c_channel_description = "民法典之婚姻家庭编法条解读"
# 频道Logo,可以直接在线找一个,或者自行托管至图床
c_channel_image_url = "https://android-artworks.25pp.com/fs08/2021/11/23/9/110_0cc601f3d1b5a8de567f2cfd7868ea57_con_130x130.png"
c_channel_language = "zh-cn"
# 与前面image_url不能一致否则不显示
c_item_image_href = "https://android-artworks.25pp.com/fs08/2021/11/23/9/110_0cc601f3d1b5a8de567f2cfd7868ea57_con.png"
# 单集音频类型
c_item_type = 'audio/m4a'
# 单集自定义地址前缀,这里测试使用了内网ip
c_item_enclosure = 'http://admin:admin@192.168.124.25:8080/Podcasts/'
# 单集音频本地存放文件夹地址
file_path = '/Users/zigma/Downloads/婚姻家庭编'
# 清除文件夹下的.DS_Store文件
os.system('find %s -name .DS_Store | xargs rm -rf' % (file_path))
#获取路径中文件夹名
dir_name = os.path.basename(file_path)
doc = Document() # 创建DOM文档对象
rss = doc.createElement('rss') # 创建根元素
rss.setAttribute('version', "2.0") # 设置命名空间
rss.setAttribute('xmlns:itunes', "http://www.itunes.com/dtds/podcast-1.0.dtd")
rss.setAttribute('xmlns:atom', "http://www.w3.org/2005/Atom")
doc.appendChild(rss)
############播客信息################
channel = doc.createElement('channel')
rss.appendChild(channel)
channel_title = doc.createElement('title')
channel_title_text = doc.createTextNode(c_channel_title)
channel.appendChild(channel_title)
channel_title.appendChild(channel_title_text)
channel_link = doc.createElement('link')
channel_link_text = doc.createTextNode(c_channel_link)
channel.appendChild(channel_link)
channel_link.appendChild(channel_link_text)
channel_description = doc.createElement('description')
channel_description_text = doc.createTextNode(c_channel_description)
channel.appendChild(channel_description)
channel_description.appendChild(channel_description_text)
channel_language = doc.createElement('language')
channel_language_text = doc.createTextNode(c_channel_language)
channel.appendChild(channel_language)
channel_language.appendChild(channel_language_text)
channel_image = doc.createElement('image')
channel.appendChild(channel_image)
channel_url = doc.createElement('url')
channel_url_text = doc.createTextNode(c_channel_image_url)
channel_image.appendChild(channel_url)
channel_url.appendChild(channel_url_text)
channel_image_title = doc.createElement('title')
channel_image_title_text = doc.createTextNode(c_channel_title)
channel_image.appendChild(channel_image_title)
channel_image_title.appendChild(channel_image_title_text)
############节目信息################
file_list = sorted(os.listdir(file_path)) # 文件名按字母排序
file_nums = len(file_list)
for i in range(file_nums, 0, -1):
file_size = os.path.getsize(file_path + '/' + file_list[i-1])
file_name = re.sub(r'^[0-9]+|\.[a-zA-Z0-9]+$', "",
file_list[i-1]) # 利用正则表达式替换掉开始序号及后缀
#print(file_list[i-1] + str(file_size))
item = doc.createElement('item')
channel.appendChild(item)
item_title = doc.createElement('title')
item_title_text = doc.createTextNode(file_name)
item.appendChild(item_title)
item_title.appendChild(item_title_text)
item_description = doc.createElement('description')
item_description_text = doc.createTextNode(file_name)
item.appendChild(item_description)
item_description.appendChild(item_description_text)
item_pubDate = doc.createElement('pubDate')
item_pubDate_text = doc.createTextNode(time.strftime(
"%a"+"," + " %b %d %Y %H:%M:%S " + "+0800", time.localtime()))
item.appendChild(item_pubDate)
item_pubDate.appendChild(item_pubDate_text)
item_enclosure = doc.createElement('enclosure')
item_enclosure.setAttribute(
'url', c_item_enclosure + quote(dir_name + "/" + file_list[i-1]))
item_enclosure.setAttribute('length', str(file_size))
item_enclosure.setAttribute('type', c_item_type)
item.appendChild(item_enclosure)
item_itunes_image = doc.createElement('itunes:image')
item_itunes_image.setAttribute('href', c_item_image_href)
item.appendChild(item_itunes_image)
# 将DOM对象doc写入文件
f = open('tel.xml', 'w')
#f.write(doc.toprettyxml(indent = '\t', newl = '\n', encoding = 'utf-8'))
doc.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()运行后即可在该Python脚本目录生成tel.xml文件。
托管XML文件
- 文件托管就比较简单了,直接丢到Gitlab的私人库即可。
- 关于Gitlab私人库的RAW地址参考如下规则:
https://gitlab.com/api/v4/projects/[projectid]/repository/files/[Filepath]%2F[Filename.rss]/raw?ref=[Branch]&private_token=[privatetoken]之后在Moon FM或者其他App订阅RSS链接即可(注意在url encode后使用)。
最后成品如图:
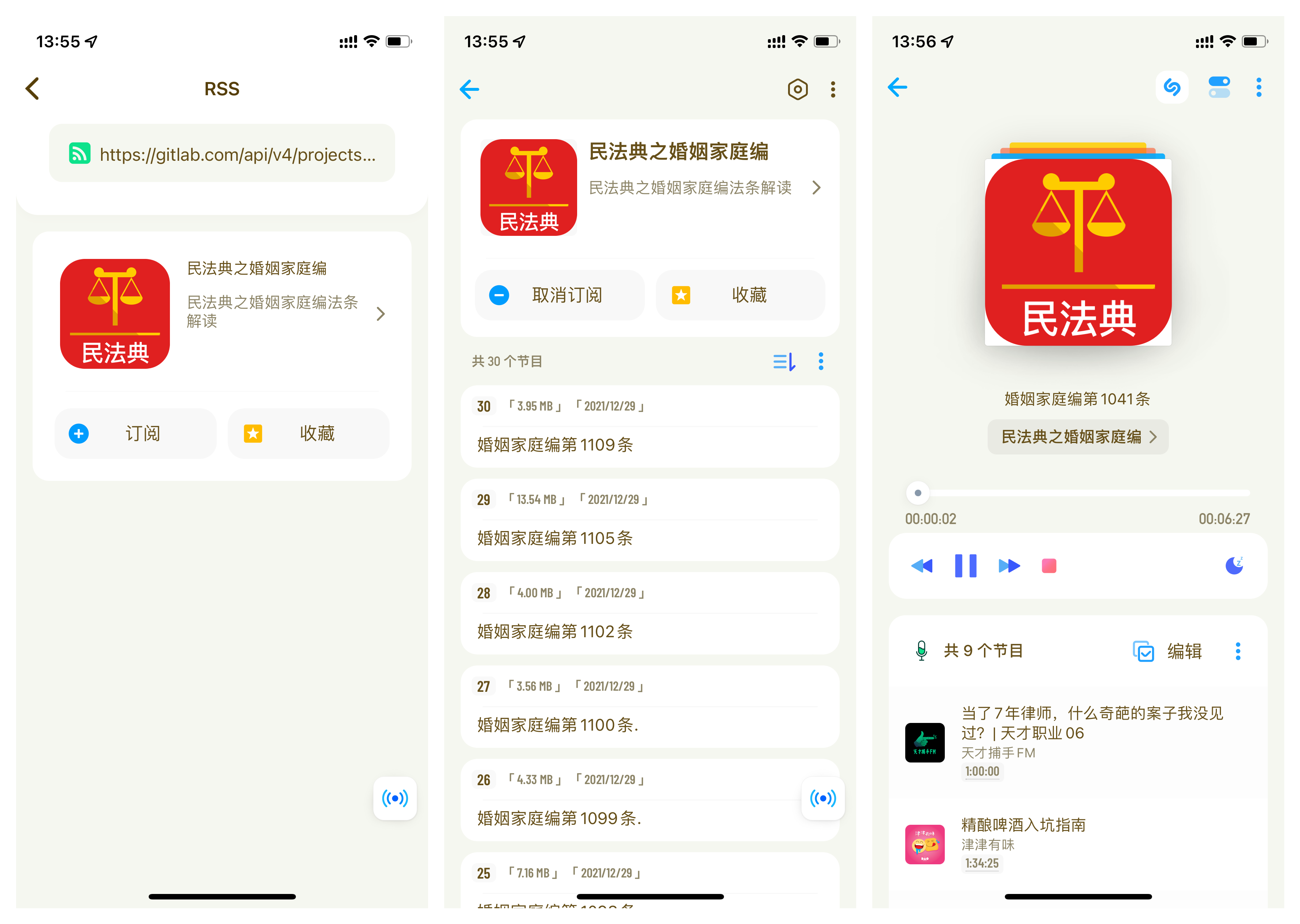
自定义电台列表
因涉及不可描述,详见我的博客
Docker搭建同步数据库
最后,把同步数据库也顺便搭建一下吧。
- 在Docker中安装CouchDB数据库,因需在公网暴露注意自定义用户名&密码;
docker run \
-p 5984:5984 \
-e COUCHDB_USER=admin \
-e COUCHDB_PASSWORD=password \
-d couchdb- 安装完后通过
http://192.168.2.2:5984/_utils利用以上用户名&密码测试登录; - 在
Config - Main config中设置couch_peruser模式;- 可能
couch_peruser选项都没有,所以需要点击右上角Add Option依次添加:
- 可能
| Section | Option | Value |
| couch_peruser | database_prefix | userdb- |
| couch_peruser | delete_dbs | false |
| couch_peruser | enable | true |
- 添加
_users数据库;
curl -X PUT http://admin:password@192.168.2.2:5984/_users \
-H "Accept: application/json" \
-H "Content-Type: application/json" \如果卡住,可以输入exit后查看主页有无_users数据库生成,没有就重复第五步,如再卡住,等待后再exit;
- 在
_users中创建用户test,需要自定的将下面test的数据库名称、用户名、密码自行修改;
curl -X PUT http://admin:password@192.168.2.2:5984/moonfm/org.couchdb.user:test \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{"name": "test", "password": "test1234", "roles": [], "type": "user"}'可以看到生成了一个userdb-xxxxxxxxxx 的数据库l
http://test:test1234@192.168.2.2:5984/userdb-xxxxxxxxxx以上即为同步地址
- 设置端口转发后即可外网访问;